3 minutes
Week1036_review
ARTS - Review 补2019.3.13
Generating Unique Id in Distributed Environment in high Scale:
大规模生成分布式系统的唯一ID
Recently I was working on a project which requires unique id in a distributed environment which we used as a primary key to store in databases. In a single server, it is easy to generate unique id like *** Oracle *** uses *sequence(increment counter for next id )* in SQL auto increment primary key column in tables.
最近我工作在一个需要生成唯一ID作为主键存在数据库的分布式环境。在一个单机环境,很容易生成唯一ID,像 ORACLE 使用 sequence(增长生成下一个ID) 在SQL表中自增主键列。
In SQL we can do it while creation of the table.
在SQL中,我们创建表时候这样做:
CREATE TABLE example (
primary key AUTOINCREMENT PRIMARY KEY,
...
);
In Oracle, we use sequence while inserting in table.
在Oracle , 我们使用序列来插入表。
CREATE SEQUENCE seq_example
MINVALUE 1
START WITH 1
INCREMENT BY 1
CACHE 10;
INSERT INTO example(primary_key) VALUES(seq_example.NEXTVAL);
In a single server, it’s pretty easy to generate a primary key, In a distributed environment, it becomes a problem because key should be unique in all the nodes. Let’s see how can we do it in a distributed environment.
There are a couple of approaches which has pros and cons both so let’s go through one by one.
在单服务器上,很容易就生成一个主键,在一个分布式环境,因为要保证键在所有节点唯一,就成了问题。在分布式环境该如何做呢?
这有两种方法各有利弊,我们一个个看。
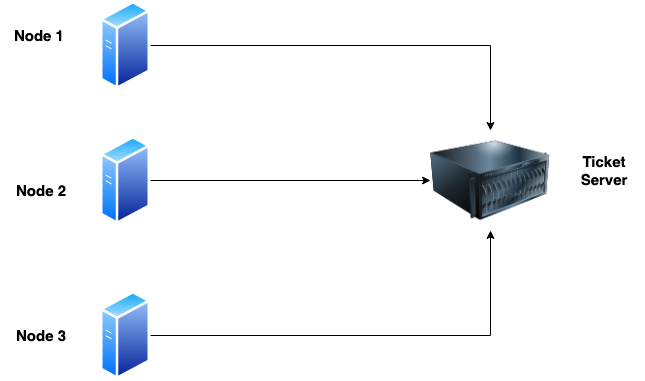
Database Ticket Servers:
These are the Centralized Auto increment servers which response with unique ids when requested from the nodes. The problem with these kinds of nodes is a single point of failure because all the nodes are dependent on this server if it fails then all nodes will not able to process further.
这些是集中式自动增量服务器,当节点请求时会返回唯一ID作响应。问题是当多个这种节点都依赖这台服务器,如果它出现故障,所有的节点都将出现问题。
UUID
UUIDs are 128-bit hexadecimal numbers that are globally unique. The chances of the same UUID getting generated twice is a negligible or very very less probability for collisions UUID contains a reference to the network address of the host that generated the UUID, a timestamp (a record of the precise time of a transaction), and some randomly generated component.
UUID 是128位全局唯一散列数字。两次生成同样的UUID机会是非常低的或者非常小的通途概率,UUID包含生成UUID的主机网络地址引用,一个时间戳(一次事务的时间片),和一些随机组件。
According to Wikipedia, regarding the probability of duplicates in random UUIDs:
Only after generating 1 billion UUIDs every second for the next 100 years, the probability of creating just one duplicate would be about 50%. Or, to put it another way, the probability of one duplicate would be about 50% if every person on earth owned 600 million UUIDs.
根据 Wikipedia , 解释随机UUID可能重复的情况:
接下来100年每秒生成10亿UUID,生成一个重复UUID的概率约50%.或者,换句话说,地球上每人都拥有600百万UUIDS, 才有50% 几率出现一次重复。
- UUID’ s does not require coordination between different nodes and can be generated independently.
UUID不要求不同节点的条件,可以独立生成。
But the problem with UUID is very big in size and does not index well so while indexing it will take more size which effects query performance.
但是UUID的问题也很大,就是尺寸很大,不能友好索引,以便提高查询性能。
Twitter Snowflake
Twitter snowflake is a dedicated network service for generating 64-bit unique IDs at high scale with some simple guarantees.
Twitter Snowflake 是一个利用几个简单保证依赖网络服务来生成64位唯一ID的高性能方法。
The IDs are made up of the following components:
- Epoch timestamp in millisecond precision — 41 bits (gives us 69 years with a custom epoch)
- Machine id — 10 bits (gives us up to 1024 machines)
- Sequence number — 12 bits (A local counter per machine that rolls over every 4096)
- The extra 1 bit is reserved for future purposes.
ID由以下组件组成:
- 精确到毫秒的时间戳 — 41 位(可以使用69年)
- 机器ID — 10位(可以使用1024个机器)
- 序列号 — 12位(每台机器本地序列号,每个都到4096)
- 额外1位为未来保留
So the id which is generated by this is 64bit which solves the problems of size and latency issues but also introduces one problem for maintaining extra servers.
That’s it
Happy Learning.
所以64位生成的ID解决了大小和延时问题,但是也引入了额外机器的问题。
以上。
学习快乐。