11 minutes
Week1037_review
Apache Kafka in Depth
In the era of Big Data, lots and lots of data(volume) are being produced every second(velocity) from various sources like social media, blogs that I am writing currently, e-commerce, etc., which gets stored across different platforms in different schemas(varieties). In order to perform any ETL (Extract, Transform, Load) operation, a messaging/streaming system is needed which should be asynchronous and loosely coupled i.e. data from various sources/clients like hdfs, Cassandra, RDBMS, application log file, etc. could be dumped at a single place at the same time without all the clients depending on each other. One of the solutions to the problem is Kafka — An open-source distributed streaming platform created by LinkedIn and later donated to Apache. It is written in Scala.
大数据时代,大量的数据在每秒钟从各种渠道像社交媒体,我在写的博客,电子商务等生产出来,被不同平台不同类别的存储起来。为了执行任意ETL(Extract 提取, Transform转换, Load装载)操作,就需要一个消息流系统,可以异步把松散耦合数据从多个数据源像HDFS(分布式文件系统),Cassandra(分布式NoSQL数据库), RDBMS(关系型数据库系统),应用日志等 同时存到一个地方,不用依赖任何客户端。一个解决方案是 Kafka, Linkedin开源捐赠给Apache的一个分布式流平台。它是用Scala写的。
Terminology 术语
Messages: It is basically a key-value pair contains useful data/record in the value section.
Topic: For multi-tenancy, multiple topics can be created which is just a feed name to which messages are published and > subscribed.
Offset: Messages are stored in a sequential form similar to commit log and a sequential id is provided to each message starting from 0.
Broker: Kafka cluster consists of brokers which are just nodes in the cluster hosting stateless server maintained by a zookeeper. Since there is no master-slave concept here, all brokers are peers. Let’s understand zookeeper first before proceeding further.
Messages: 它基本上是一个 键值对,值上包含有用的数据/记录。
Topic: 对于多租户,多个创建多个主题,这只是将消息发布和订阅的源名称。
Offset: 偏移量。消息存储在一个有序列的表中,类似于提交日志和一个有序ID给每个消息,从0开始。
Broker: 代理。kafka 集群由代理组成,代理只是集群中的节点,托管在zookeeper维护的无状态服务器。这里没有主从概念,所有的代理都是同级。更深入前我们先了解zookeeper.
What is Zookeeper and Why is it needed in Kafka Cluster?
Zookeeper is a system for distributed cluster management. It is a distributed key-value store. It is highly-optimized for reads but writes are slower. It consists of an odd number of znodes known as an ensemble. In Kafka, it is needed for:
- Controller Election: All the read and writes from a partition for particular topics happen through the leader of the replica. Whenever the leader goes down, a new leader is elected by the zookeeper.
- Configuration of Topics: Metadata related to a topic that whether a particular topic is sitting in the broker, how many partitions are there, etc. are stored at the zookeeper end and are continuously in-sync whenever a message is produced.
- Access Control List(ACL) of a topic is maintained at a zookeeper.
什么是zookeeper ,为什么kafka集群中需要它?
zookeeper是一个分布式集群管理系统。它是分布式键值对存储。对读操作是高度优化的,但是写就慢些。它由奇数个znodes组成,被称为簇。在kafka,它被用来:
- 控制选举:分区中所有特定主体的读写都是由通过副本的leader进行的。一旦leader停止,一个新leader被zookeeper选举。
- 主题配置:与某个主题相关的元数据,该主题是否位于代理中,有多少分区,等等,存储在zookeeper端,并在消息产生时持续同步。
- 一个主题的操作控制列表维护在zookeeper
Why Kafka?
Some of the key features of Kafka, which is a challenge for conventional messaging system makes it more popular:
- High Throughput: Throughput stands for the number of messages in a second (rate of messages) that can be processed. As we can partition the topic which can spread across different brokers, we can achieve thousands of reads and writes per second.
- Distributed: A distributed system is one which is split into multiple running machines, all of which work together in a cluster to appear as one single node to the end-user. Kafka is distributed as it stores, read and write the data on several nodes called a broker which along with Zookeeper collectively creates an ecosystem known as Kafka Cluster**.**
- Persistence: The message queue is maintained completely on a disk rather than keeping it in memory and several copies/replica called as ISR (in-sync replica)of the same data can be stored across different nodes. Hence, there is no chance of data loss due to failover scenarios and makes it durable.
- Scalability: Any system can be scaled horizontally or vertically. Vertical scalability means adding more resources like CPU, Memory to the same nodes and incurs a high operational cost. Horizontal scalability can be achieved by simply adding a few more nodes in the cluster which increases the capacity demands. Kafka scales horizontally means we can add a new nodes/broker in the cluster whenever we run out of capacity/space.
- Fault-Tolerant: If we have n topics each having m partitions then all n*m partitions will be replicated on q brokers if we set the replication factor to q. Hence, making it tolerant as a factor of q-1 i.e. we can afford the failure of q-1 broker nodes. Replication factor should always be less than or equal to the number of brokers as violating this condition will end up having two copies of the same replica on a single broker which doesn’t make sense.
为啥是kafaka?
kafka的一些关键特性,对传统消息系统是个挑战,这使得它更流行。
- 高吞吐量。吞吐量代表一秒内处理消息的数量(消息效率)。我们可以对分布在不同代理上的主题进行分区,实现每秒千次读写。
- 分布式的:一个分布式系统就是分割成多台机器运行的系统,在一个集群里一起工作对终端用户来说是一个节点展示。kafka的分布式是它的读写数据发生在几个被zookeeper管理的叫做代理的节点上,它与zookeeper一起创建了一个称为kafka集群的生态系统。
- 持久化:消息队列完全维护在一个硬盘而不是保持在内存中,几个副本叫做ISR(in-sync副本)被不同节点存储相同数据。因此,不存在因灾备切换导致的数据丢失的可能,使它更持久。
- 可扩展性:任何系统都可以水平、垂直伸缩。垂直伸缩意味着给相同节点增加更多资源,像CPU,内存,导致业务成本很高。水平扩展可以通过简单的增加一些集群节点来实现,提高容量。Kafka水平扩展意味我们可以在超过容量空间时在集群中增加一个新的 节点/代理 。
- 容错性:如果我们有n个主题,每个有m个分片,所有的n*m个分片 将会复制在q个代理上,如果我们设置代理书是q个。因此我们能承受q-1个代理节点出错。复制因子应该始终小于或等于代理的数量,因为违反这个条件将导致同一个副本在一个代理上有两个副本,这是没有意义的。
Note: Kafka guarantees at-least-once delivery by default and allows the user to implement at most once delivery by disabling retries on the producer and committing its offset prior to processing a batch of messages.
注意:Kafka默认情况下保证最少一次传递,并允许用户通过在处理一批消息之前禁用生成器上的重试和提交其偏移量来实现最多一次传递
Hands-on:
Kafka scala library can be downloaded from here: http://kafka.apache.org/downloads which contains the zookeeper as well.
动手做,先下载。
After extraction of zip, let’s say HOME_DIR = kafka_2.12–2.3.0/
解压后设置 HOME_DIR = kafka_2.12-2.3.0/
First of all, we need to turn the zookeeper up by providing the dataDir name and port in HOME_DIR/config/zookeeper.properties.
首先,打开zookeeper
./bin/zookeeper-server-start.sh ../config/zookeeper.properties
Zookeeper will be up and running on 2181 port by default. Now, we need to start Kafka server. the script is located in the bin folder. Server related config can be made in HOME_DIR/config/server.properties. Let’s make
zk默认使用2181端口运行,然后我们需要启动kafka服务。
broker.id=101
listeners=PLAINTEXT:localhost:9091
logldirs=some_log_dir/kafka-logs-1
./bin/kafka-servert-start.sh ../config/server.properties
This will start a Kafka server at port 9091. Cheatsheets:
Creating a topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 partitions 1 --topic topic1
Describing a particular topic:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic topic1
Deleting a topic:
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic topic1
Note: Partition once set to a particular value cannot be decreased, it can only be increased.
注意分片一旦设置为特定值就不能减少,只能增加。
How Producer writes a message?
生产者怎么写信息的?
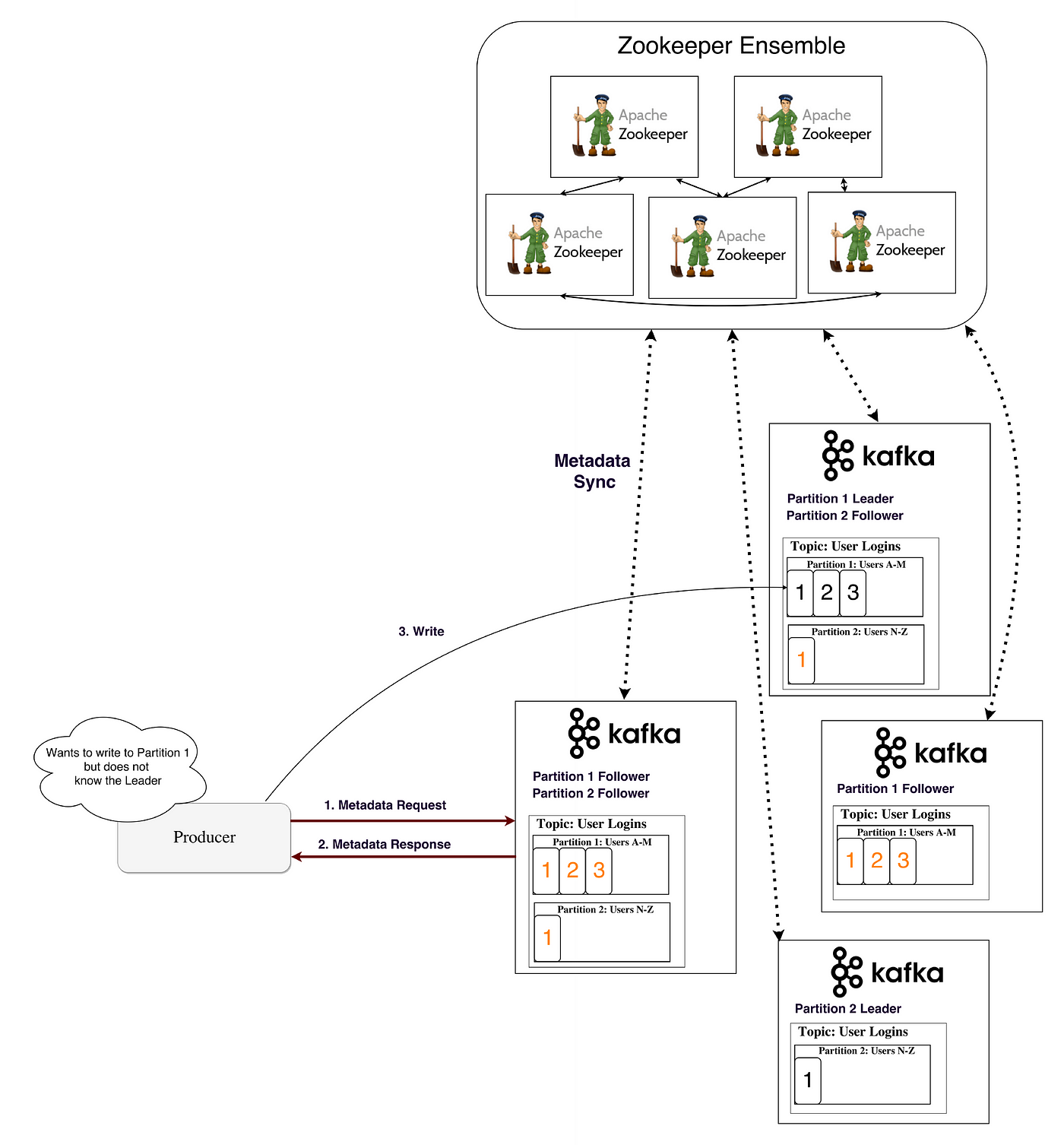
The Producer first fetches the Metadata of the topic in order to know which broker needs to be updated with the message. Metadata is also stored at the brokers and is in continuous sync with the zookeeper because the zookeeper nodes are generally very less as compared to the no. of brokers. So, many producers would like to connect to the zookeeper to access the metadata and the performance degrades. Now, once the producer gets the metadata about the topic and partition, it writes the message in logs of the leader broker node and followers (ISR) copy it.
生产者首先拉取主题的元数据以便于知道那个代理需要更新消息。元数据也被存在代理上并与zookeeper保持同步,因为zookeeper节点通常非常少,比代理节点数目少得多。所以很多生产者乐意去连接zookeeper操作元数据,这样会导致性能降低。现在一旦生产者获得主题和分片元数据,它就写消息进leader代理的日志,跟随者会复制。
This writes operation can be either synchronous [i.e. the status about the message acknowledgment is returned to the producer only when the followers also copy that message in their log] or asynchronous [i.e. only the leader is updated with the new message, status is sent to the producer]. Retention Period: Messages on a disk can be persisted for a particular duration of time known as retention period, after that period automatic purging of the old messages will happen and will no longer be available for consumption. By default, it’s set to 7 days.
这种写操作可以既不同步[消息状态承认返回生产者仅当follower也复制信息到他日志]也不异步[learder用新消息更新,状态发给生产者]。保留周期:磁盘上的消息可以持续一段特定的时间,这段时间称为保留期,在此之后,将自动清除旧消息,不再可供使用。默认情况下,设置为7天
The message can be written to a topic in three Strategies:
a. send(key, value, topic, partition): specifically providing the partition in which writes needs to happen. This is not encouraged to use as it may create an imbalance in partition size.
b. send(key, value, topic): Here, default HashPartitioner is used to determine the partition in which the message will be written by finding the hash of key and taking mod with no. of partition for that topic. Our own custom Partitioner can also be written.
c. send(key=null, value, topic): In this case, the message is stored in all the partition in a round-robin fashion.
消息可以用三种策略写到主题:
a. send(key, value, topic, partition): 明确提供要写入的分区。不推荐使用,可能造成分区大小不平衡
b.send(key, value, topic) : 默认哈希分区被用来确定消息写入那个分区,使用key 哈希mod主题分区编号.我们自有自定义分区也能写入。
c. send(key=null, value, topic): : 这种情况,消息循环方式存储在所有分区
A producer can send the messages in the form of a batch to improve efficiency. Once a batch reaches a particular size limit, it is dumped to the queue once. However, the offset will be sequential only for all the individual message and are deflated at the consumer end before passing it to the consumer API.
一个生产者可以通过批量发送消息提高效率。一旦一个批任务到达分区上限,会备份到队列一次。但是,偏移量仅对所有单独的消息是连续的,并且在将其传递给消费者API之前在消费者端减少。
Producer API :
A Kafka producer is an application that can act as a source of data in a Kafka cluster. A producer can publish messages to one or more Kafka topics using the API provided by the Kafka jar files/dependencies. A properties object containing the configuration on storing the message needs to set before sending the message. Main classes ProducerRecord, KafkaProducer, Callback.
生产者API
一个kafka生产者是一个作为集群数据源的应用。一个生产者可以发布消息到一个多个kafka主题通过 kafka jar文件提供的API。一个属性对象包括储存信息的配置,需要被发送消息前设置。主类 ProducerRecord, KafkaProducer, Callback.
public static final String TOPIC_NAME = "topic1";
private static Properties createProperties() {
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9091,localhost:9092");
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return properties;
}
private static void produce() {
Producer<String, String> producer = new KafkaProducer<>(createProperties());
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, "SyncKey", "SyncMessage");
try {
RecordMetadata recordMetadata = producer.send(record).get();
System.out.println("Message is sent to Partition no " + recordMetadata.partition() + " and offset " + recordMetadata.offset());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} finally {
producer.close();
}
}
How consumer retrieves a message?
The consumer also retrieves the messages in the same way producer writes it by looking up into the metadata and reads the message from the leader partition. As Kafka is very fast and can get real-time messages, a single consumer will certainly have latency in reading a big chunk of a message from a topic known as consumer lag.
消费者如何取数据?
消费者使用生产者写入数据同样的方式,浏览元数据读leader分区来获取数据。kafka很快,可以获得实时消息,单个消费者在从某个主题读取大量消息时肯定会有延迟,即所谓的消费者延迟。
To overcome this problem, A Consumer group can be created which consists of several consumers having the same group id. Each consumer connects with a unique partition divided equally among all the consumers. The assignment of the partition to a particular consumer is the responsibility of Group Coordinator — One of the brokers in the cluster is nominated for this role. In order to manage the list of active consumers, all the consumer of a group sends their heartbeat to the group coordinator. The number of consumers in a group should be less than or equal to the number of partitions in that particular topic, violating the condition will end up in a situation where a consumer sits idle.
为了克服此问题,可以创建一个“消费方”组,该“消费方”组由多个具有相同组标识的消费者组成。 每个使用者都连接有一个唯一的分区,该分区在所有使用者之间平均分配。 将分区分配给特定的使用者是组协调员的责任-群集中的一个经纪人被提名担任此角色。 为了管理活动使用者的列表,组中的所有使用者将他们的心跳发送到组协调器。 组中使用方的数量应小于或等于该特定主题中的分区的数量,违反条件将最终导致某个用户闲置的情况。
More than one consumer can read a single topic at the same time. Now, in order to remember till which offset the particular read, storage known as consumer offset as a hidden topic - __consumer_offsets is provided to store the last offset of a partition read by the consumer of a particular group.
The Consumer offset has the key as — > [Group Id, Topic, Partition] and value — > [Offset, …]
多个消费者可以同时读取单个主题。现在为了记住那个分区读的,存储为消费者偏移量 作为隐藏主题 topic-_consumer_offsets 用来存储一个分区组的消费者分区读取的最后偏移量。
Consumer API:
Similar to producer API, Kafka provides classes to connect to the bootstrap servers and get the messages. Deserializer needs to be written when passing a message of other than standard data types.
Java API of Kafka for Producer and Consumer can be found here: https://github.com/ercsonusharma/learnkafka
和生产者API一样,Kafka 提供类来连接服务获得消息。
How Kafka is Fast?
Kafka follows a certain strategy which is part of its design to make it perform better and faster.
- No Random Disk Access: It uses a sequential data structure known as an immutable queue where read and write operation is always constant time O(1). It appends the message at the end and read from the beginning or from a particular offset.
- Sequential I/O: Modern operating systems allocate most of their free memory to disk-caching and are faster for storing and retrieving sequential data.
- Zero Copy: The data from disk is unnecessarily loaded into the application memory as it is not being modified at all. So, instead of loading it to the application, it sends the same data from the kernel context buffer over the socket, NIC buffer and to the network.
- Batching of messages: Several messages are grouped together in order to avoid the multiple network call.
- Message Compression: Before transferring the message over the wire, it is compressed using compression algorithm like gzip, snappy, etc. and decompressed at the consumer API layer.
kafka这么做得到快的?
kafka遵循的一个确切策略使它设计的表现更好更快。
- 没有磁盘随机访问:它使用一个序列的数据结构被称为不变队列,读写操作总是O(1).它从最后拼接消息,从开始读取,或者从一个确定位置
- 有序IO:现代操作系统分配把绝大部分空闲内存分配给磁盘缓存,更快存储检索有序数据。
- 0复制:来自于磁盘的数据无序加载进应用缓存,因为它从未被修改。所以不用加载进应用,通过socket,NIC 缓冲发送相同数据从内核缓冲到网络。
- 批信息:几个信息组合一起避免多次网络调用
- 消息压缩:网络传输消息之前,先用压缩算法像gzip,snappy等压缩, 消费者api调用再解压缩
How the data reside on the Broker instance / physical disk?
All the messages in a broker are stored in the log directory (log-dir-1) configured in the config file before turning the Kafka server up. Inside that directory, a folder containing a partition of a particular topic can be found in the format as topic_name-partition_number e.g. topic1–0. The __consumer_offsets topic is also stored in the same log directory.
数据如何保存在代理实例/物理磁盘上?
所有的代理消息存存储在启动kafka之前配置文件里配置的日志目录(log-dir-1)。该目录下,一个文件包括一个分区确定的主题,可以被发现通过 topic_name-partition_number 如 topic1-0. _consumer_offsets 主题也存储在相同日志目录。
Inside the partition directory of a particular topic, Kafka segment file 0000–00.log, index file 0000–00.index and time index 0000–00.timeindex can be found. All the data belonging to that partition are written in an active segment as a new segment file is created when the old segment size or time limit is reached. Indexes map each offset to their message’s position in the log. Since offset is sequential binary search is applied to find a data index in log file at a particular offset.
Log Compacted Topics
Duplicate Keys are marked for deletion from segment file. The value here can be updated and deleted by passing a null value to a particular key.
Thanks for reading! Watch this space for advanced Kafka story. Please do read my other stories as well.